

“Multimodal” загвар нь олон төрлийн өгөгдлөөс мэдээлэл боловсруулж, нэгтгэх боломжтой машин сургалтын загваруудын анги юм. Нэг төрлийн оролтыг зохицуулдаг уламжлалт загвараас ялгаатай нь “multimodal” загвар нь текст, зураг, аудио гэх мэт өөр өөр төрлийн оролтыг нэгэн зэрэг боловсруулж, суралцах боломжтой.
Зураг 1: “Multimodal” загвар нэгэн зэрэг ажиллах боломжтой өгөгдлийн төрлүүд
Энэ загвар нь хүмүүс мэдээллийг хэрхэн хүлээн авч, боловсруулахад тусалдаг тул чухал ач холбогдолтой юм. Жишээлбэл, бид зургийг үзэхдээ зургийн агуулгыг бүрэн ойлгохын тулд контекстийг авч үздэг. “Multimodal” загвар нь хиймэл оюун ухаанд энэ түвшний ойлголтыг авчирч, илүү боловсронгуй, контекстийг ойлгодог програмуудыг хөгжүүлэх зорилготой юм.
“CLIP” загвар
CLIP (Contrastive Language-Image Pre-training) нь 2021 оны эхээр OpenAI компани танилцуулсан бөгөөд тус загвар нь олон талт сургалтын салбарт томоохон дэвшлийг авчирсан. CLIP нь зураг болон текстийн тайлбарын хамаарлыг ойлгож, холбож чаддаг учраас бусад загвараас ялгардаг.
Зураг болон түүнд харгалзах текстийг тогтмол хэмжээст вектор болгон хөрвүүлэхийн тулд кодлогч ажилдаг. Бидэнд текст болон зураг хоёулаа байгаа тул текст болон зургийн кодлогч хоёулаа хэрэгтэй болно.
CLIP нь эдгээр хоёр тусдаа кодлогчийг ашигладаг:

Зураг 2: CLIP кодлогчийн архитектур. Текстийг текст кодлогчоор, зураг нь дүрс кодлогчоор боловсруулагддаг. Энэ нь [1] бүрийг төлөөлөх вектор хувиргалт үүсгэдэг.
CLIP-ийн сургалтын үйл явцын гол цөм нь “contrastive” буюу ялгаатай сургалт юм. Зорилго нь зураг текстийн харгалзах онцлог векторуудыг ойртуулахын зэрэгцээ тохирохгүй харгалзах векторуудыг холдуулах явдал юм.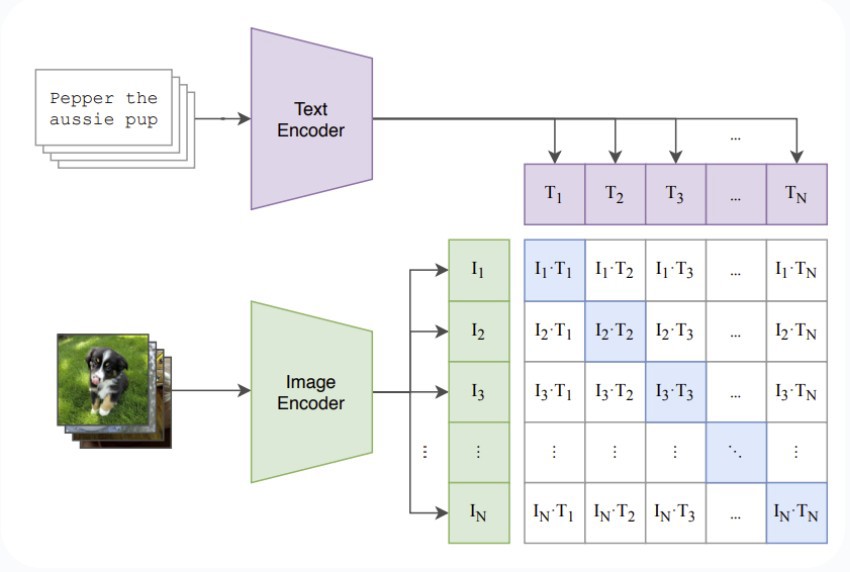
Зураг 3: CLIP загварын сургалт
Энэ нь тодосгогчтой алдагдлын функцаар дамждаг. Сургалтын багц дахь зураг болон текстийн хувьд CLIP нь боломжит бүх векторуудын косинусын ижил төстэй байдлыг тооцдог. Дараа нь загвар нь зөв векторуудын ижил төстэй байдлыг дээд зэргээр нэмэгдүүлж, буруу векторуудын хувьд үүнийг багасгадаг. Энэ процесс нь зургийг текстийн тайлбартай үр дүнтэй нийцүүлэх байдлаар загварыг сургадаг.
Сургалт явагдсаны дараа CLIP нь нэмэлт нарийн тохируулга хийлгүйгээр янз бүрийн ажлыг гүйцэтгэх боломжтой. Энэ чадварыг тэг сургалт гэж нэрлэдэг.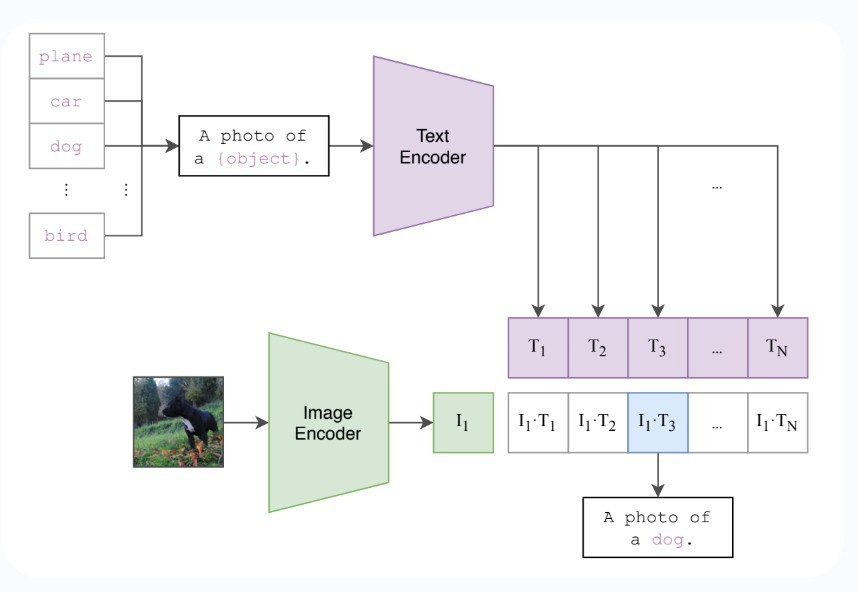
Зураг 4: Текстийн өгөгдлийн багц ангилагчийг үүсгэн дараа нь тэг сургалтад ашигладаг.
CLIP-ийн “Zero-Shot” сургалтаар зураг, текстийг ойлгох, хооронд нь холбох чадварыг ашигласнаар бид ангилал, зураг хайх, зургийн текстийн тайлбарыг бий болгох зэрэг ажлуудыг гүйцэтгэх боломжтой. Энэ нь илүү ойлгомжтой, олон талт хиймэл оюун ухааны системийг бий болгох шинэ боломжуудыг нээж өгдөг бөгөөд мэдээллийг саадгүй нэгтгэж, боловсруулах боломжтой юм.
Эх сурвалж: https://medium.com/@paluchasz/understanding-openais-clip-model-6b52bade3fa3
Мэдээ бэлтгэсэн: Мэдээллийн технологийн салбарын ЭША Б.Номуундалай